CapFriendly Systems Design
CapFriendly (2016-2024) was a website for NHL fans, the media, and even teams (they were so indispensible, they were acquired by the Washington Capitals). They covered many different facets in hockey player management: salary caps, draft inventory, transactions, and more. All while handling millions of visitors every month and keeping up with the Free Agency rush every July. The website was quick and helped fans better understand the nuances of managing the cap with many different details. Questions like “What does Restricted Free Agent mean?” to “What Free Agents are available and at what price” were easily and quickly found. It also let users create their own teams via the Armchair GM feature, a fantastic feature that gave people insight into the macinations of managing a team.
I’ve interviewed for many Software Engineer roles that put a heavy emphasis on Systems Design - the process of designing the architecture, components, and interfaces for a system so that it meets the end-user requirements. As a full-stack engineer, part of the job is knowing how the whole system fits together. Perhaps you can write really efficient code and solve LeetCode problems, but can you explain the purpose of the system? How should different applications interact and solve those requirements? What should the database schema look like? Who will use it?
Let’s dig into some of the major areas of CapFriendly’s system design:
Product Requirements
What are people going to come to the website for? How can we serve a variety of customers? How will it make money?
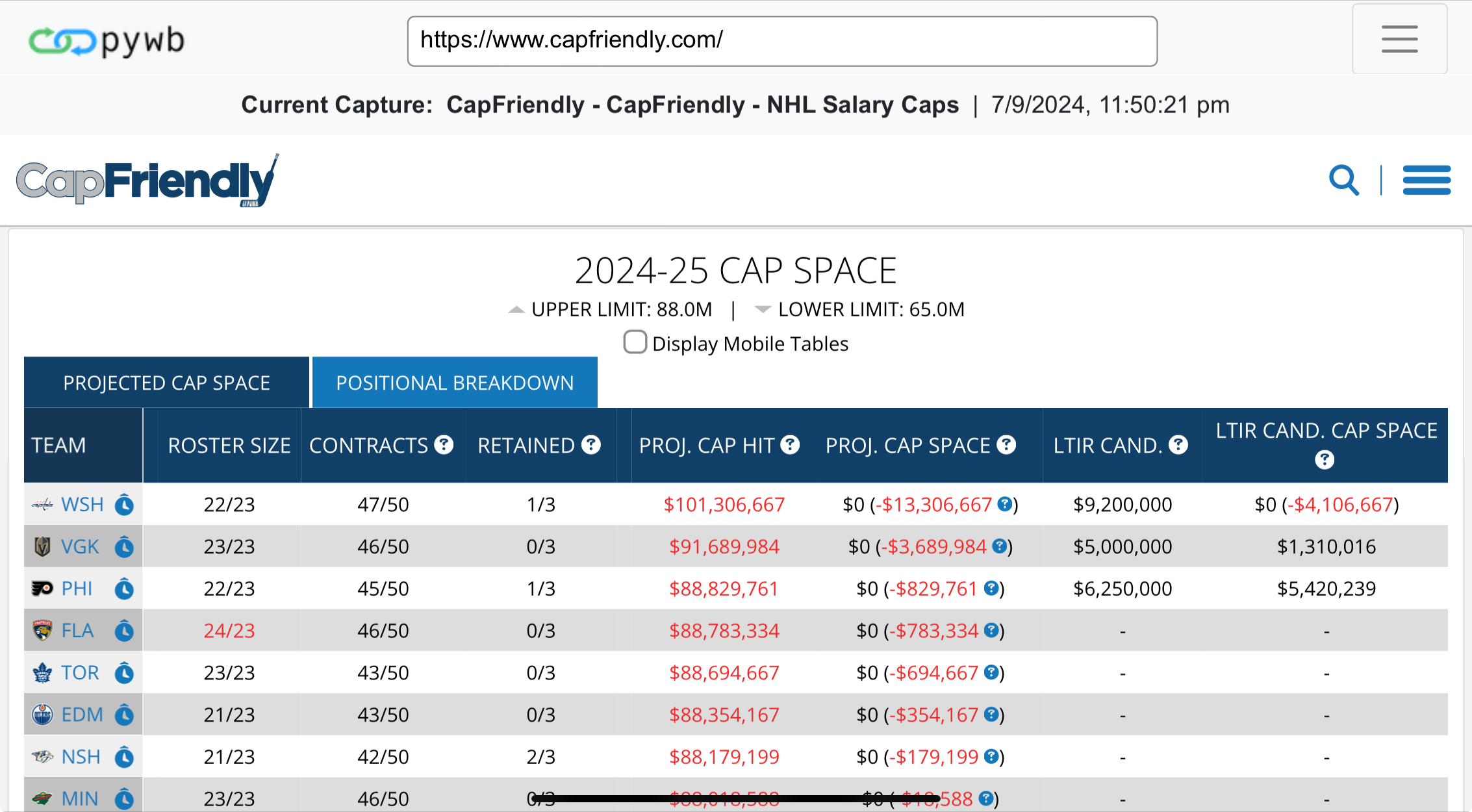
CapFriendly, like CapGeek before it, was launched to help NHL fans to better understand how teams in the NHL were managing their rosters and salary caps. Before those sites were around, many contract details were hidden from the public. Teams would often not willingly disclose salary or term length, or if there were any No Move/Trade Clauses. Media members could get this info, but it wasn’t in one place. So the ultimate raison d’être of these cap sites: Get contract data to the public.
The rest of the site’s major features flow neatly from this requirement.
- Team Cap Space and Assets - Are teams in compliance? What draft picks do they hold? Retained salaries?
- Player Salary Lookup - Who can fit into your favorite teams?
- Calculators - What if scenarios: What’s the cap hit on buying out a contract? Offer Sheets?
- Transactions - Trades, Drafts, Waives, Signings, Injuries
- Simulators - Let fans get into the mindset of a GM by giving them easy tools to make transactions.
All of these features can be accomplished with two primary ingredients: contract and transaction data, and knowing the rules that govern those contracts and transactions. The latter also makes the site extremely useful in acquisition; the people running the site have been trusted by the teams and clearly understand the nuances of managing the team’s resources. While fans were the primary goal, it’s revealing that media and teams leaned on the website as well. Having all this data in a central & public repository was seen as unnecessary thing by the league; clearly many stakeholders at clubs and journalists disagreed with the NHL on this point.
The website would eventually lean on ads and a premium service to make money; quite necessary when the traffic of the site was easily in the millions of users per month. Becoming a massive hit is an exciting prospect but also brings plenty of issues. Scaling the tech, paying for more servers, and finding ways to get paid can stress a small team of developers. I believe they may have done some deals with teams; this would surely solve some monetary problems and subsidize the public traffic, but it also represents a diverging sets of interests. The public may want features that go in line with the original purpose of public contract and cap data. The teams would instead need features that would help the team win. We’ll never get to see how the site would continue to evolve to fit the public’s needs; instead the system’s purpose will be changed to “how can the Capitals win?” which will require a much different system. (More on that later)
Major Components
What applications will be needed? Which database is right for the handling of data? What APIs will we interface with to get external data? What web framework will be used?
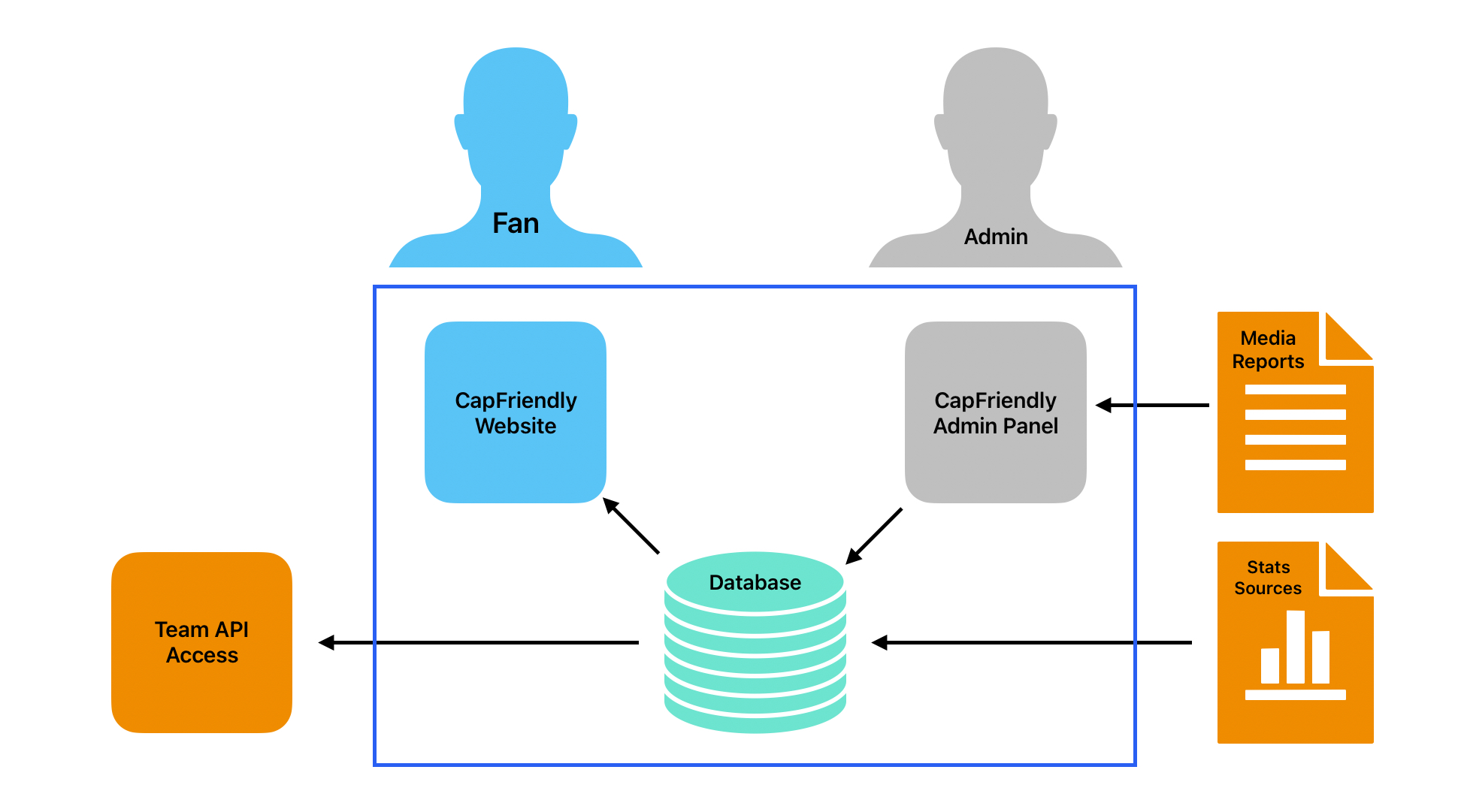
Without knowing the internals of the website, I can surmise some of the major portions of their system.
- Admin Panel - Media reports, scouting reports, trade entries, transactions: all of this would need to be entered into the system. There are multiple libraries that handle this data entry + data validation. Contract entry would need to have multiple things checked off before it could be submitted into the system. Or in the case of a six-way-trade entering what teams are involved, making sure they have the assets that the trade is using, and what conditionals are in place.
- Public Website - Everything that we see. Team dashboards, player history, the forums, the Armchair GM tool, etc. Given the JavaScript-lite nature of the website, I’ll guess that it’s a Django or Ruby on Rails app that does a lot of server rendering. This can be a big benefit for mostly-read-only website; caching and load balancing is much easier with these setups.
- The Database - The secret sauce of the website. The hard work. Some may say it’s easy to build such a website, but the difficulty is understanding and gathering all the data necessary to populate it. Calculating daily cap hits requires perfect data about player contracts, transactions, and business rules.
Data Model
The data schema would have to store a lot of different types of data. Some of these may also need snapshots at any given day, especially the cap hit tracking. Some example tables and views:
- Simple storage - Teams, Players, Trades, Waivers, Drafts, Scouting Reports
- Materialized Views - UFAs, League Cap Dashboard, Team Cap Dashboard
- Tranformations - Salary Cap Projcections, Historical Cap Hits
- Forum Tables - Posts, Threads, Users, Armchair GM teams
I want to call out the last part, because it’s what made the site special for many hardcore users. While I’d guess 99% of users just looked up their favorite team or pending UFAs, 1% of users created many, many Armchair GM teams. Around 1.5 Million URLs in my big crawl were related to this feature. Storing these user-created teams requires it’s own set of database tables so that it can store a snapshot of the player contracts, depth position on the team, what trades would be necessary for the final roster, and the impact of transactions on the team’s salary cap.
All of this has to be stored away from the main data. It could have been all done on the front-end and not saved in a database like my Expected Goals calculator, so a big kudos to the CapFriendly team giving people the fantasy of modifying their favorite team and building conversations around it in the Forum.
Other considerations
Some things to consider are questions around scaling the website, caching pages, user registration, forum moderation. There’s also the API that partners could use; I also did not dive deep into their premium offerings. The transformations and calculations to project out many years. All of this takes a lot of different skills and expertise, both in the general software development and business specific needs. I hope to do more architecture reviews in the future and cover these aspects.
What’s next?
As of July 10th, CapFriendly is no longer public. They’ve closed the site and now are full time members of the Washington Capitals. Chris Patrick has been promoted to General Manager and will need to direct some changes to the website for internal use within the Front Office. So what might the CapFriendly crew do with it now? Here are a few things I’d suggest they take to make the best use of the software already created:
- As a front office user - I want to securely access the site, so that it’s protected and I have access to add notes on players and teams. // SSO logins will protect this, train folks on how to use the backend for adding data as necessary.
- As a scout - I want to be able to add scouting reports directly on each page, so that it can be one place. // Create a place on every page that lets the most recent notes be seen. Pivot the page from just being about to contract, to a one-stop shop.
- As a data analyst - I want to have up-to-date stats, so that we make better decisions // Use the integration framework to bring in data about each player, whether that’s continuing to pay for data from Elite Prospects and Evolving Hockey or building it in-house.
Ultimately the goal is to use CapFriendly like a salesperson might use Salesforce: It’s a one-stop shop for many people to collaborate and make decisions, all while having a single source of truth.
The Archive
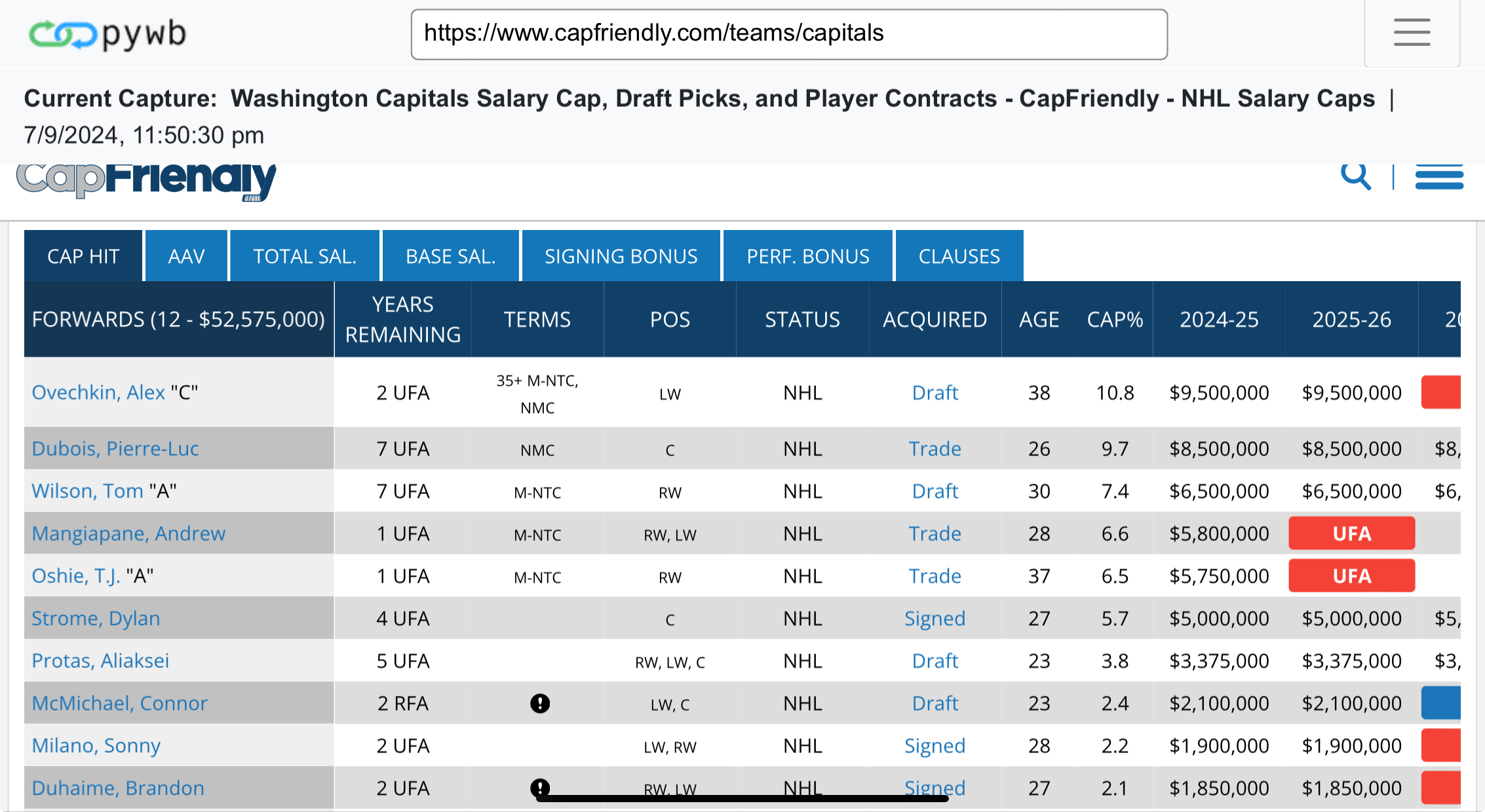
While CapFriendly is now offline for most of us, what’s next? First, PuckPedia has done a fantastic job of picking up the baton. But if you’re nostalgic for CapFriendy, need to double check some data, or just want to relive some of your Armchair GM teams, I’ve created a WARC archive on the Internet Archive that crawled the site shortly before the shut down.
The important files:
capfriendly-full-crawl-2024-07-05.warc.gz- This is 44GB and contains all the forums. If it wasn’t captured here, it’s not going to be in any other archive. Crawled from July 5th to July 8th. (Over 2.5M web requests!)capfriendly-short-crawl-no-forums-2024-07-09.warc.gz- This is 775MB and Is very lightweight. It has the teams and most of the players, but may be missing some data. I captured this on July 9th, right before the shutdown.capfriendly-short-crawl-no-forums-2024-07-03.warc.gz- Crawled July 3rd after the free agent rush, and is 3GB.
In order to view these files like the Wayback Machine, there are a few options:
- Replay Webpage - Useful for the lightweight crawls: It is totally in-browser. Download the file, load it into the page, and then navigate to
https://www.capfriendly.comwhen prompted. - pywb - Python library for capturing and serving archives. This is the ideal setup for researchers (or cough teams) - Download the 3 archives and run this as a server. To do that:
$ mkdir cf-archive && cd cf-archive
$ python3 -m venv archive-venv
$ source archive-venv/bin/activate
$ pip install pywb
// follow the instructions at https://pywb.readthedocs.io/en/latest/manual/usage.html#using-existing-web-archive-collections to setup the archives that you downloaded
$ wayback
Then go to the server and search for the main URL - and then you’ll have it running locally!
In Closing
Hope this was useful, and I want to provide my congratulations to the Davis’s and (selfishly) I hope this means great things for the Washington Capitals. But I also share the bittersweet feelings that a public resource was lost. It must have been a difficult decision to shut down something that had been beloved by so many people. Hopefully this article can help people appreciate the hard work they did and revisit it if they so choose by checking out the archive.
If you have any questions about this article, please reach out to me at my email or my LinkedIn.